
AIの予測計算、中身を覗いてみた
- Yuka Kudo

- 5月11日
- 読了時間: 4分
「AIが予測を出す」とは、具体的にどのような計算なのでしょうか。
本記事では、ニューラルネットワークの基本的な構造から、順伝播・活性化関数・目的関数まで、数式レベルで解説します。
ニューラルネットワークとは
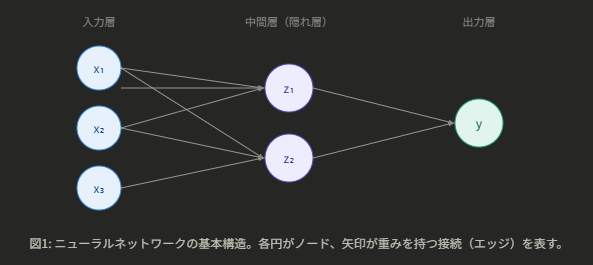
ニューラルネットワークとは、脳の神経細胞(ニューロン)のつながりをモデル化した機械学習のアルゴリズムです。複数の入力値を受け取り、重み付きの演算を繰り返すことで予測値を出力します。
ネットワークは大きく3種類の層(レイヤー)で構成されています。
入力層(Input Layer):データを受け取る入口
中間層 / 隠れ層(Hidden Layer):特徴を抽出する処理段
出力層(Output Layer):最終的な予測値を出す出口
中間層を2層以上重ねたネットワークが「ディープラーニング」と呼ばれます。各層のノード同士は「重み(weight)」と呼ばれる係数を持つ接続(エッジ)でつながっています。
順伝播の計算
入力層から出力層へ向かって値を計算していく処理を「順伝播(Forward Propagation)」と呼びます。計算は大きく2ステップで行われます。
ステップ1:線形変換
入力ベクトル x、重み行列 W、バイアスベクトル b を使って、次の計算で中間層の値 u を求めます。
u = Wx + bたとえば入力が3次元、中間ノードが2個の場合、具体的には次のようになります。
u1 = w11・x1 + w12・x2 + w13・x3 + b1
u2 = w21・x1 + w22・x2 + w23・x3 + b2この計算が「入力値と重みを掛け合わせて足し込む」という、ニューラルネットワークの基本動作です。
ステップ2:活性化関数による非線形変換
線形変換を重ねるだけでは、ネットワーク全体として線形な関係しか表現できません。そこで各ノードは「活性化関数 f」を適用し、非線形性を加えます。
z = f(u)この z が次の層への入力になります。
代表的な活性化関数3種
ニューラルネットワークでよく使われる活性化関数を3つ紹介します。
■ シグモイド関数
z(u) = 1 / (1 + exp(−u))入力に応じて0〜1の値を出力します。かつてよく使われましたが、層が深くなると「勾配消失」という問題が起きやすいため、現在の深層学習では主役の座を譲っています。
■ ReLU(正規化線形関数)
z(u) = max(0, u)入力が正の場合はそのまま出力し、負の場合は0にします。シンプルな構造でありながら勾配消失を起こしにくく、現代のディープラーニングで広く使われている標準的な選択肢です。
■ ソフトマックス関数
a(u) = exp(uk) / Σ exp(um)多クラス分類の出力層で使われます。全ノードの出力値の合計が1になるため、「各クラスに属する確率」として解釈できます。

数値で確認する順伝播の流れ
実際に数値を使って計算してみましょう。
入力を x = [1, 2, 3] とし、活性化関数には ReLU を使います。
(1)線形変換
u1 = 3×1 + 1×2 + 2×3 + 0 = 11
u2 = −2×1 + (−3)×2 + (−1)×3 + 0 = −11(2)活性化
z1 = max(0, 11) = 11
z2 = max(0, −11) = 0 (3)出力層での計算
y = 2×11 + 3×0 = 22ポイント:
ニューラルネットワークの実際の計算は、加算と乗算で構成されています。
そのため非常に高速に並列処理が可能です。
目的関数:誤差をどう測るか
モデルが出力した予測値と正解値のズレを定量化する関数を「目的関数(損失関数)」と呼びます。学習ではこの値を小さくするようにパラメータを更新します。
■ 平均二乗誤差(Mean Squared Error)
L = (1/N) Σ (tn − yn)²回帰問題でよく使われます。各データ点での二乗誤差を平均したものです。
上の例(予測値22、正解値10)で計算すると、
L = (1/1) × (10 − 22)² = 144となります。
■ 二値交差エントロピー(Binary Cross Entropy)
L = −Σ [ tn・log yn + (1 − tn)・log(1 − yn) ]犬か猫かなど、2クラスに分類する問題で使われます。予測値はシグモイド関数で0〜1の値に変換されます。
■ 交差エントロピー(Cross Entropy)
L = −Σn Σk tnk・log ynk多クラス分類で使われます。正解クラスに対応するノードの出力確率の対数をとり、その総和で評価します。ワンホットベクトル(正解クラスのみ1、それ以外は0)を正解ラベルとして使います。
まとめ
本記事で解説した内容を振り返ります。
ニューラルネットワークは「入力層 → 中間層 → 出力層」で構成される
順伝播は「線形変換(Wx + b)→ 活性化関数」の繰り返し
ReLUは勾配消失に強く、現代の深層学習の主流な活性化関数
目的関数で予測誤差を定量化し、パラメータの更新方向を決める
次のステップとしては、目的関数の値を小さくするためにパラメータをどう更新するかを扱う「誤差逆伝播法(Backpropagation)」の理解が重要になります。
コメント